
















Wir verwenden Cookies, um Ihnen die optimale Nutzung unserer Webseite zu ermöglichen. Es werden für den Betrieb der Seite nur notwendige Cookies gesetzt. Details in unserer Datenschutzerklärung.
Datenschutzerklärung
Impressum
Hier beginnt der Hauptinhalt dieser Seite
Das Experimentierfeld FarmerSpace beschäftigt sich mit dem digitalen Pflanzenschutz an Zuckerrübe und Weizen. Ein Fokus liegt auf Blattkrankheiten und Methoden des Unkrautmanagements. Auf dem Experimentierfeld wird ein Spektrum von Sensoren und Kameras auf Robotern oder Drohnenplattformen eingesetzt. Ziel ist es, den Prozess der digitalen Geräte von der Marktverfügbarkeit bis zum Einsatz auf den Betrieben zu beschleunigen. Denn die Werkzeuge bringen nur einen Mehrwert, wenn sie in der Praxis benutzt werden. Das ist aber nur möglich, wenn es eine Plattform gibt, die die Funktion und den Mehrwert unabhängig beschreibt, testet und die Ergebnisse öffentlich zeigt wie das Experimentierfeld FarmerSpace.
Koordiniert vom Institut für Zuckerrübenforschung in Göttingen und mit weiteren Projektpartnern, wie dem Institut für Agrartechnik der Universität Göttingen, der Landwirtschaftskammer Niedersachen und dem Fraunhofer-Institut für Optronik, Systemtechnik und Bildauswertung (IOSB), werden digitale Werkzeuge für das Feld erforscht.
Landwirtinnen und Landwirte kennen ihre Felder und wissen, was dort passiert. Sie können den Zustand eines Ackers visuell beurteilen: Trockene Stellen, Krankheitsbefall, Mangelerscheinungen oder der richtige Zeitpunkt für Maßnahmen werden abgeleitet, indem sie regelmäßig „auf die Felder fahren und schauen“. Im Versuchswesen wird diese Einschätzung als „Bonitur“ bezeichnet. Diese wird benutzt, um einen visuellen Eindruck der Pflanzenentwicklung, speziell unter dem Einfluss von Krankheiten oder Trockenheit, für den Vergleich verschiedener Sorten zu bekommen. Sie wird von geschultem Personal durchgeführt, das die Merkmale einer Kultur oder Krankheitsbildes erkennen kann.
Die Übertragung der manuellen Bonitur in eine digitale Bonitur ist herausfordernd: Um große Flächen zu bonitieren wird viel Fachpersonal benötigt. Je mehr Wiederholungen der Versuche bonitiert werden, desto verlässlicher ist die statistische Auswertung. Die digitale Bonitur landwirtschaftlicher Versuche und Flächen ist eine gute Möglichkeit hierfür.
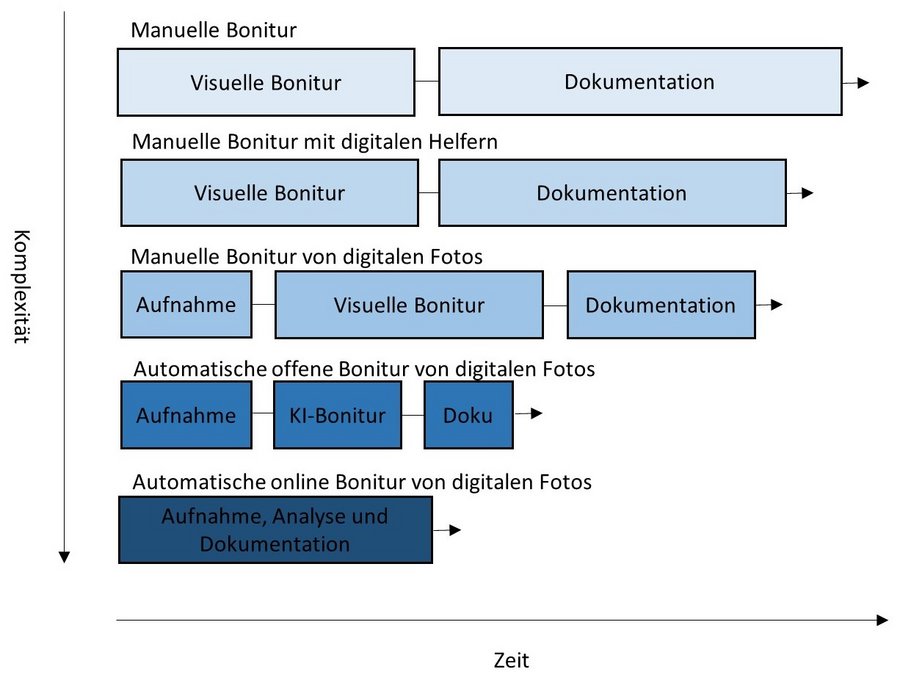
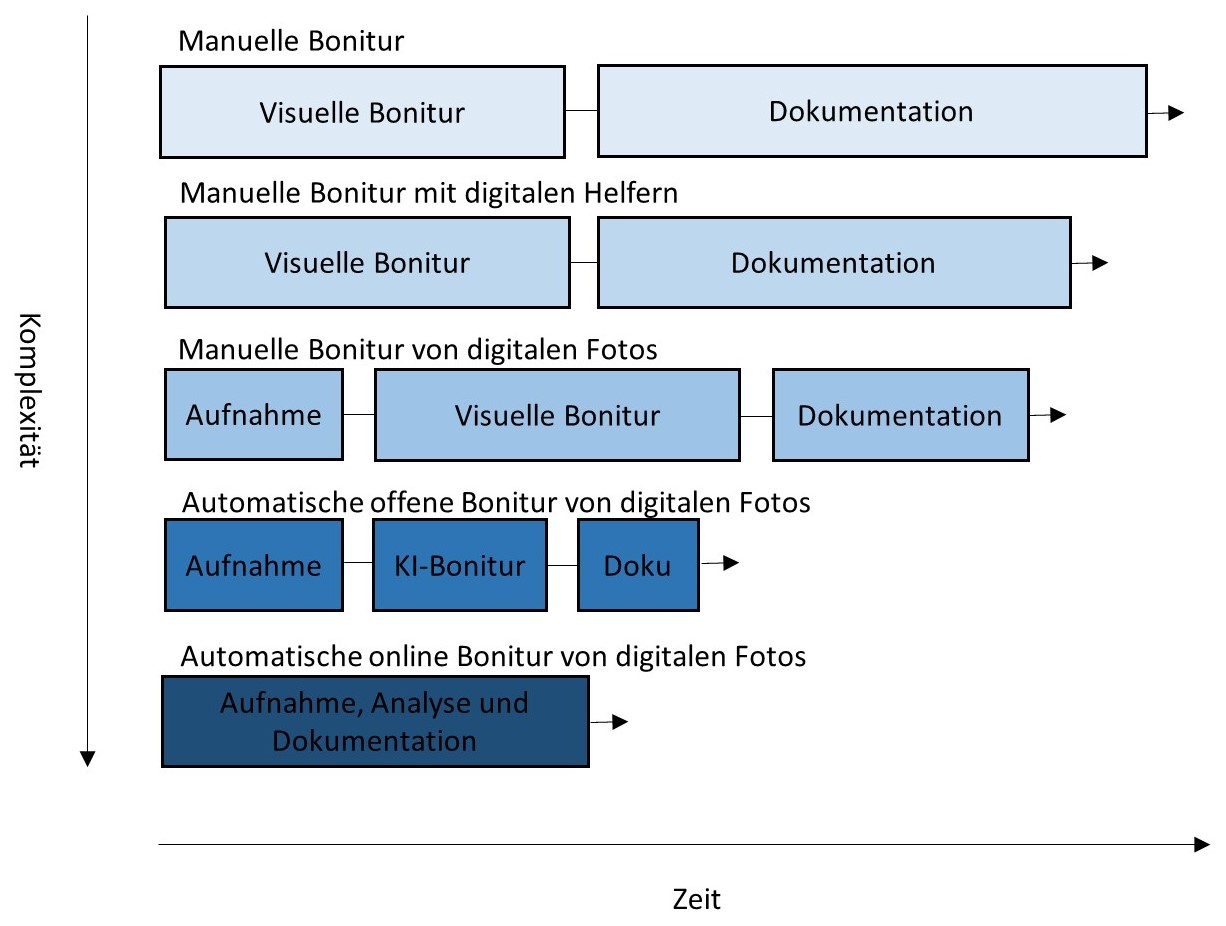
Der Begriff „digitale Bonitur“ unterteilt sich in mehrere Kategorien oder Level, die mit steigender Zahl einen höheren Grad der Automatisierung aufweisen:
Die wesentlichen Arbeitsschritte neben der eigentlichen Bonitur und der Dokumentation sind die Datenaufnahme sowie die Analyse durch die KI.
Überfliegungen von Äckern mit Drohnen sind heute leicht zu bewerkstelligen, da Kombinationen von Drohne und Kamera marktverfügbar sind. Die rechtlichen Anforderungen an Versicherung sowie Kenntnisnachweisen sind geringer je kleiner die Drohne und je größer die räumliche Entfernung zu unbeteiligten Dritten ist.
Je nachdem, welche Parameter auf dem Feld erfasst werden sollen, ist eine hohe Auflösung der Kamera wichtig. Eine Bonitur zu einem Krankheitsbefall mit zum Beispiel Cercospora beticola in Zuckerrüben benötigt eine höhere Auflösung als eine Biomasseschätzung im Mais.
Die Auswertung erfolgt mit Methoden der künstlichen Intelligenz. Dazu werden die Daten geteilt. Ein Teil wird genutzt, um das Modell zu trainieren, das heißt das Modell wird angelernt. Dazu wird beschrieben, wie zum Beispiel eine Infektion oder eine gesunde Pflanze aussehen und das Modell trainiert die Unterscheidung. Wie gut dieses Modell funktioniert, wird auf einem anderen unbekannten Datensatz getestet. Sind die Daten den Trainingsdaten ähnlich, ergibt sich eine hohe Genauigkeit. Sind sie unterschiedlicher, ergibt sich eine geringere Genauigkeit. Um also ein Modell zur Erkennung von Cercospora zu erstellen, werden viele Daten von Zuckerrüben benötigt: unterschiedliche Sorten, verschiedene Beleuchtungs- und Aufnahmewinkel, unterschiedliche Auflösungen und Kameratypen, auf unterschiedlichen Böden und in den verschiedenen Wachstums- und Krankheitsstadien.
Dahinter steckt ein lernendes Modell für die Unterscheidung von Pflanzen und Unkraut, oder der Erkennung von Krankheiten auf Pflanzen. Das Modell lernt dabei unterschiedliche Unterscheidungsmuster je nach verwendetem Sensor auf Grundlage von visuellen Mustern (RGB-Kameras), Geometriestrukturen (3D) oder der spektralen Signatur (multi-/hyperspektrale Kameras). Durch den Abgleich mit manuell genommenen Referenzdaten wie einer Proberodung/Teilernte, der menschlichen Bonitur oder einer chemischen Analyse erfolgt der Realabgleich.
Diese riesige Menge an Daten zeigt, warum Daten heute das „neue Gold“ sind. Sobald sie verfügbar sind, ist es möglich, teure manuelle Arbeit durch ein Modell hochautomatisiert durchführen zu lassen.
Aktuell sind menschliche Expertinnen und Experten der Goldstandard im Feldversuchswesen. Wer im Feld ist, kann gezielt Pflanzen genauer betrachten. Die Drohne bleibt beschränkt auf den reinen Blick von oben. Zudem hängt die automatisierte Auswertung vom Trainingsdatensatz des benutzten Modells ab. Schon heute ergibt sich dadurch eine hohe Genauigkeit, jedoch mit einem Fehler. Wird dieser Fehler zu Gunsten der hohen Flächenleistung aktueller KI-Routinen toleriert, stellen die neuen digitalen Methoden der Bonitur einen effektiven und schnellen Weg dar, große Flächen für landwirtschaftliche Versuche oder auch in der Praxis zu analysieren. Dabei werden die Bestandesinformationen, wie Pflanzengesundheit und Biomasseentwicklung, auf dem Feld quantifiziert.
Autonome Maschinen, die auf dem Feld effizient und ohne manuelles Zutun Aufgaben verrichten, sind schon in ganz Deutschland anzutreffen. Möglich ist dies durch Fortschritte im Maschinenbau, Neuentwicklungen im Akku- und Elektronikbereich, der breiten Verfügbarkeit von Mobilfunk und GPS-Signalen sowie der maschinennahen Implementierung von KI-Modellen zur schnellen und automatisierten Analyse von Bilddaten.
Speziell Roboter für das Unkrautmanagement sind seit einigen Jahren für Zuckerrübe und im Gemüseanbau marktverfügbar. In den folgenden Ausführungen zu dieser Art des Unkrautmanagements steht die Zuckerrübe im Fokus.
Grundsätzlich gibt es zwei Funktionsweisen für Steuerung von Hackrobotern. Positionsbasierte Roboter nutzen eine hochgenaue Standortinformation bei der Aussaat des Saatguts und dem anschließenden Hacken. Kamerabasierte Systeme analysieren digitale Bilder und steuern die Hackwerkzeuge dementsprechend.
Beide Systeme sind marktverfügbar und werden in der Praxis eingesetzt. Sie besitzen Limitierungen in der Anwendung und der funktionelle Bedarf an den Roboter muss geklärt werden.
Der positionsbasierte Ansatz nutzt das Standortsignal des GPS-Netzwerkes kombiniert mit einem Korrektursignal für eine finale Positionsgenauigkeit von wenigen Zentimetern. Bei der Saatgutablage wird gespeichert, wo die Pille abgelegt wurde. Diese Daten werden beim Hackdurchgang genutzt: Die Hackwerkzeuge werden anschließend so gesteuert, dass sie dort, wo die Pillen abgelegt wurden, nicht hacken. Bei dieser Art des Hackens ist der Schritt der Pillenablage und Erfassung der Position der einzelnen Pflanzorte essentiell.
Es wird nicht kontrolliert, ob die Pflanze überhaupt oder an anderer Stelle aufläuft. Daher wird entweder nicht gehackt, obwohl keine Pflanze an der Position steht. Oder eine Pflanze wird weg gehackt, weil diese etwas verrollt ist.
Der marktverfügbare Repräsentant für den positionsbasierten Ansatz ist der FD20 des Herstellers Farmdroid ApS (Dänemark). Farmdroid nutzt eine langsame Fahrt mit eher filigranen Hackwerkzeugen, um eine Fläche von circa 20 Hektar unkrautfrei zu halten. Nur durch die permanente Fahrt des Roboters können die Unkräuter bereits im Auflaufen oder in sehr frühen Stadien entfernt werden. Insgesamt sind die Hackwerkzeuge kleiner dimensioniert. Größere Unkräuter können durch den FD20 nicht mehr beseitigt werden und wachsen durch.
Kamerabasierte Systeme können zum reinen Hacken eingesetzt werden. Sie säen nicht selbst und nutzen eine betriebsübliche Aussaat. Ausgehend von digitalen Bildern erfolgt die Analyse direkt auf dem Gerät. Hierzu werden effiziente KI-Modelle eingesetzt. Diese nutzen annotierte Trainingsdaten, um nicht nur zwischen Boden und Pflanze zu unterscheiden, sondern auch zwischen Kulturpflanze und Beikraut. Zusätzlich kann die Reihenausrichtung mit ausgewertet werden. Diese Informationen steuern die Hackwerkzeuge und die weitere Fahrt.
Die Qualität des kamerabasierten Ansatzes hängt stark vom zu Grunde liegenden Trainingsdatensatz ab: Wird die Rübe nicht erkannt, wird sie weg gehackt. Wird das Beikraut nicht erkannt, weil es zu klein ist, oder fälschlicherweise als Rübe angesehen, erfolgt keine Behandlung.
Der kamerabasierte Ansatz und dessen Integration in einen Roboter erfolgt durch den Farming GT der Firma Farming Revolution. Hier wird ein hochauflösendes Kamerasystem genutzt, gekoppelt mit einer KI-basierten Auswertung und verbunden mit autonomer Hacktechnik.
Die Firma Ecorobotix (Schweiz) bietet eine Integration in eine Herbizidspritze zur Unkrautkontrolle am Schlepper an. Die Kombination von Kamera, Auswertung und Düsensteuerung an der Spritze ermöglicht so eine höhere Schlagkraft im Vergleich zu reinen Robotersystemen.
Für Betriebsleiterinnen und Betriebsleiter wird es zunehmend schwerer, Arbeitskräfte für handarbeitsintensive Tätigkeiten zu gewinnen. (Hack-) Roboter, die relativ neu am Markt sind, können diesem Problem entgegenwirken und Mitarbeitende entlasten. Technikbegeisterte Landwirtinnen und Landwirte nutzen auf ihren Betrieben teilweise schon Technik, die auch in den Robotern genutzt wird: Dazu zählen zum Beispiel intelligente Hacktechnik mit Kamerasystemen und Spurführung.
Weitere Werkzeuge und Maschinen, mit denen Landwirtschaft betrieben wird, sind hinsichtlich ihrer Handhabung mit der „neuen“ Technik wenig vergleichbar. Der Informationsbedarf auf landwirtschaftlichen Betrieben ist daher groß. Es wird immer wichtiger, dass sich die landwirtschaftliche Praxis weiterbildet und mit den Zukunftstechnologien auseinandersetzt. Dadurch werden die Arbeitsweisen der Systeme verstanden, sodass bereits bei Anschaffung ein detailliertes Wissen vorhanden ist.
Anbieter entsprechender Weiterbildungsangebote sind beispielsweise die Akademie Burg Warberg, Agronym e. V. sowie lokale Volkshochschulen.
Dr. Stefan Paulus
Institut für Zuckerrübenforschung an der Universität Göttingen
Heim, R. et al. (2022): Digital weed management – New trends for weed scoring in sugar beet. Sugar Industry (2022), 147(6), 343-351, doi.org/10.36961/si28804
Experimentierfeld Farmerspace an der Universität Göttingen: https://www.farmerspace.uni-goettingen.de/
Letzte Aktualisierung 08.01.2024
Wir verwenden Cookies, um Ihnen die optimale Nutzung unserer Webseite zu ermöglichen. Es werden für den Betrieb der Seite nur notwendige Cookies gesetzt. Details in unserer Datenschutzerklärung.
Datenschutzerklärung
Impressum

{kind=link}